Let's get it started!
As a requirement for the course IFT6266h16, this blog will document my struggles with the course project. The task is to classify images of cats (meaw-meaw!) against images of dogs (woof-woof!). I will start with a quick analysis of the dataset.
I have downloaded the zip files and converted them to HDF5 using Fuel. The sad
news is that the size of dogs_vs_cats.hdf5 is 17 gigabytes, whereas the zip archives
for the training and testing were together less than a gig. This suggests that HDF5 contains uncompressed bitmaps. A quick look into the code confirms this hypothesis.
All right, let’s look inside
In [6]: dvc = DogsVsCats(['train'])
In [7]: dvc.num_examples
Out[7]: 25000
# This is 2 times less than MNIST, which let's me hope
# that training won't take that long.
In [12]: shapes = [data[0].shape for data in dvc.get_example_stream().get_epoch_iterator()]
In [13]: min_dimension = [min(x, y) for d, x, y in shapes]
In [17]: pyplot.hist(min_dimension)
# Let's see what are the sizes of the imagesThe result is below:
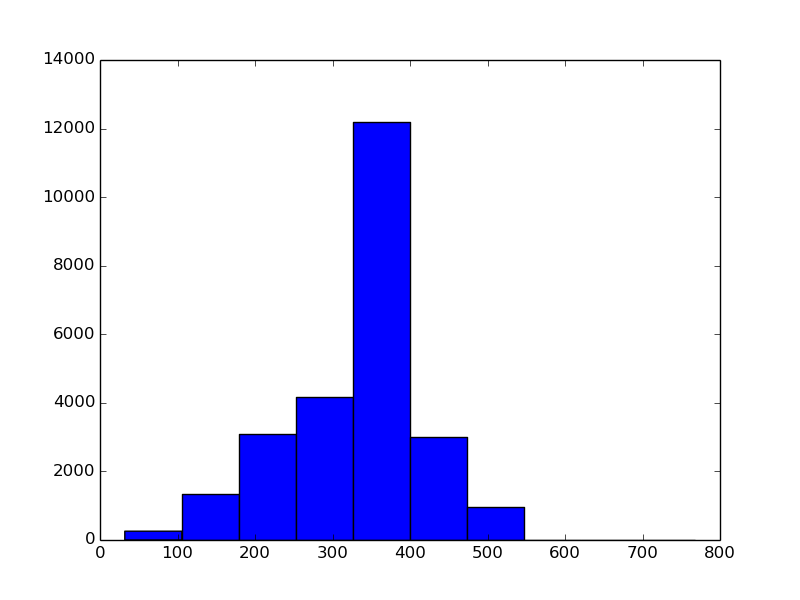
We can see that the dataset contains pixels of very different sizes, meaning
that we will have to upsample some of them. Let’s also look at the aspect ratios:
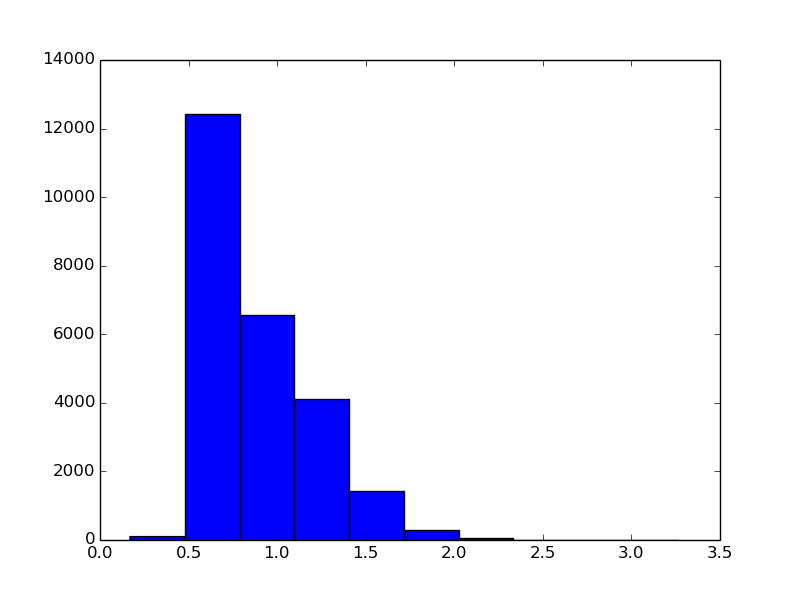
We can see, that only a fraction of the images are squares, and that the majority of themare somewhat “vertical”, i.e. the height is greater than the length. Nevertheless, I will start with square crops of a modest 128x128 size, to keep the cost and the complexity of the approach down. It would be cool to select a 128x128 crop intelligently, using some sort of an attention mechanism, but I will get something simple to work first.