Analysis of my first attempt
It is time to analyze the log produced by the first attempts to decide in which direction to move. Here are the plots of the cost and misclassification error rates. Please do not be suprised by validation error being always lower, it is because of the smart windowing used to compute it.
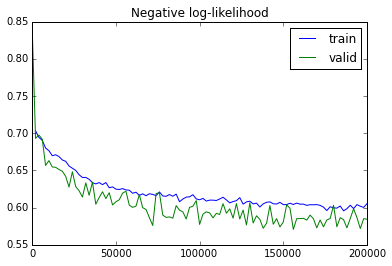
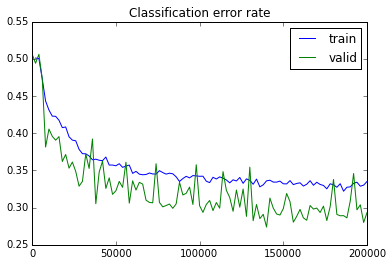
These curves indicate pretty clearly that I did not fit the data well. Let’s check the initialization and training methods and see what can be done.
Initialization
All the biases are set to zeros. As for the weights, some arbitrary-looking distributions were used:
convnet.layers[0].weights_init = Uniform(width=.2)
convnet.layers[1].weights_init = Uniform(width=.09)
convnet.top_mlp.linear_transformations[0].weights_init = Uniform(width=.08)
convnet.top_mlp.linear_transformations[1].weights_init = Uniform(width=.11)I had very positive experience with uniform distribution of width 0.1 in my research, but 0.2 seems somewhat dangerous. On the other hand, I have ReLUs in my model, and saturation should not be that big of an issue. Also, the units in the first layer have much less inputs than the units in other layers, so maybe having large weights for them is fine after all. On other hand, in AlexNet paper the initial weight distribution is Gaussian with 0.01 variance.
Training method
The training method I used was simple SGD with 0.1 learning rate. I should definitely be able to do better than that! Also, the plot of the gradient norm seems somewhat weird:
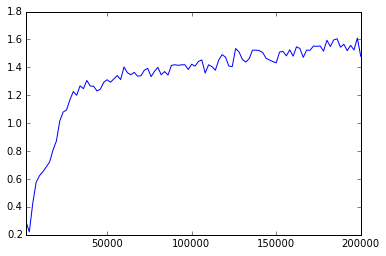
Normally, the gradient norm should decrease in the course of the training. Perhaps my learning rate is too large.
What to do next
The first thing on my todo list is to try to RMSProp. I like the idea of using just sign of the gradient, because in my experience its magniture is often rather deceiving.