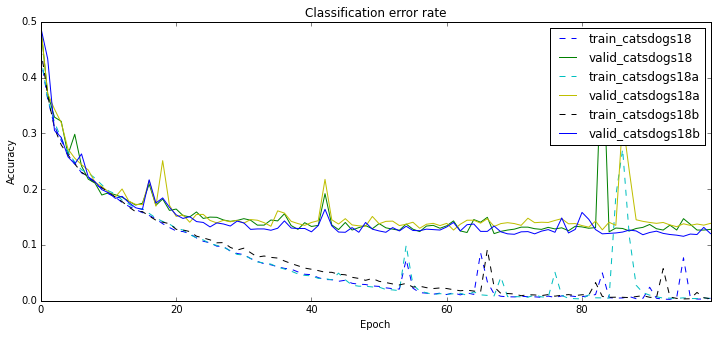
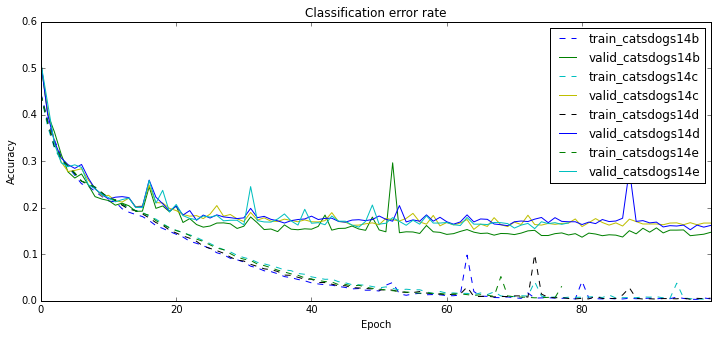
On network architecture and variance of results - 87.87%
How many convolutional and pooling layers should my network have?
Famous convnets from the literature are all built in such a way that the last convolutional layer produces an output with rather small width and height:
- 5x5 for LeNet
- 11x11 for AlexNet
- 7x7 for VGG
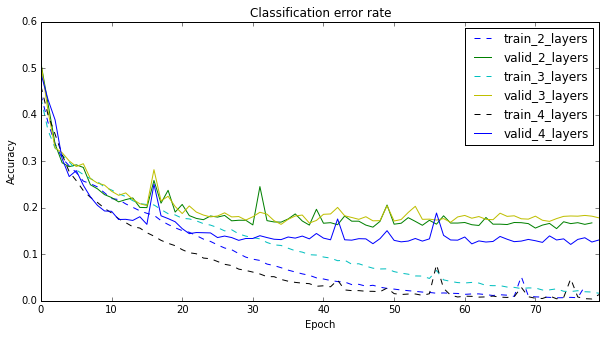
My LeNet version is very similar to the original LeNet (the difference is that I have zero padding), but it has to process images of 128x128 instead of 32 x 32. This means that my current architecture does not have enough translation invariance and probably also has way too many parameters. I should have much more subsampling, and possibly, more convolutional layers.
To check this hypothesis, I did something very simple: tried adding 1 and 2 more layers, together with pooling and subsampling. The results are below. It is interesting, that adding the 3rd layer does not help as much as adding the 4th.
Finally, not the first time in my life I notice that neural network training has quite a bit of variance in it. Below I show two families of experiments with the same models and parameters. A naked eye is enough to see that some of the runs are clearly better than others. I find this very disturbing. Of course, one can never fully eliminate the possibility of a bug, but I checked everything quite carefully.