VGG, stride, and data augmentation - 94.8%
LeNet is old and not trendy any more. Famous paper by Oxford’s Visual Geometry Group (VGG) argues that convolutional masks should be smaller and the network should be deeper. In order to try their approach, I simply replace each 5x5 convolution with two 3x3 convolutions applied after another.
But hold on, can one really apply a drastic change to the architecture and not break anything? You got me, at first, the network would not even start to train and the gradients were close to zero. I quickly figured though that this is because my initialization scheme is not good. Units from the first layer had just 90 incoming connections and needed larger weights.
Fortunately, there is a more or less principled way to initialize very non-homogeneous networks, and it was described in this paper by Xavier Glorot et al.. Nothing too fancy, it just selects the width of the uniform distribution so that the variance of the singal is preserved as it travels forward and backward in the network. Applying it immediately made my VGG-like network trainable.
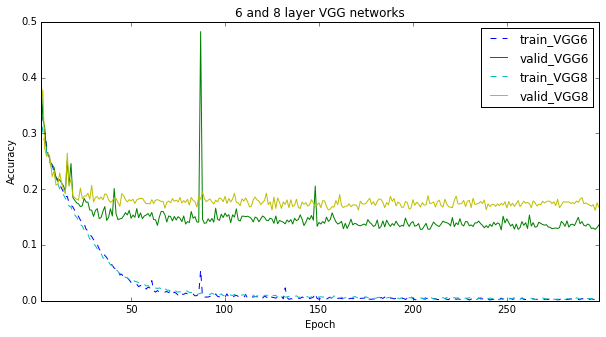
Without regularization, results were not too encouraging:
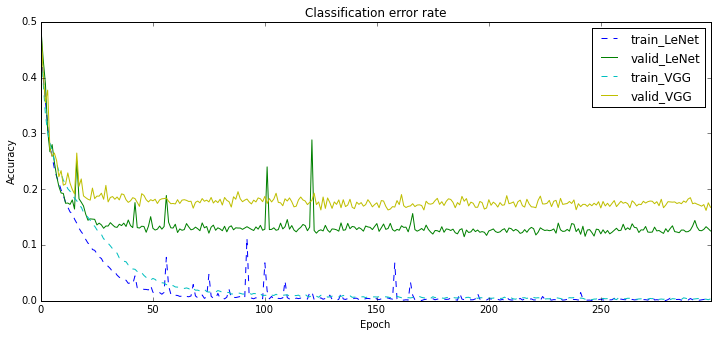
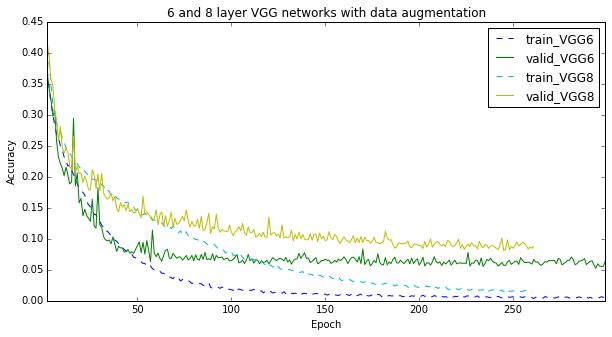
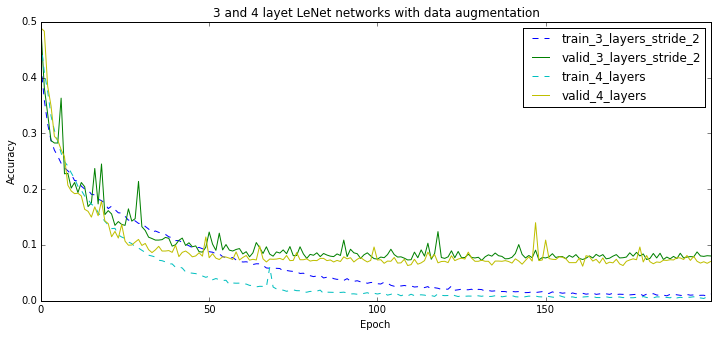
But I am used to the fact that more complex models are prone to overfitting. So I added data augmentation. Specifically, I changed the fixed minimal dimension of an image to 150. Now, an 128x128 input for the network is selected from an at-least 150x150 image.
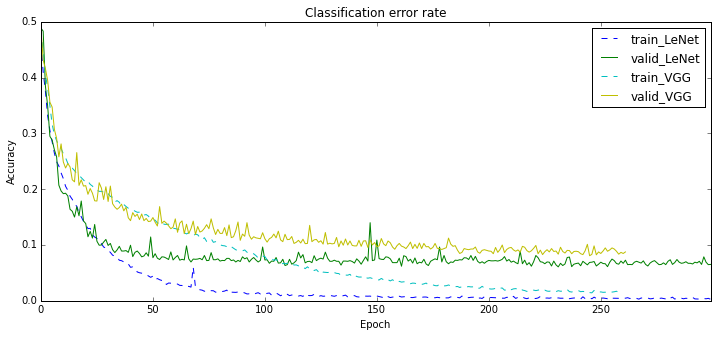
The results are below and they exceeded all my expectations. With data augmentation both networks do nearly twice less errors! Do not tell me any more about translation invariance of the convnets, I don’t buy it!
VGG is still lagging behind, though its learning curve looks somewhat promising.
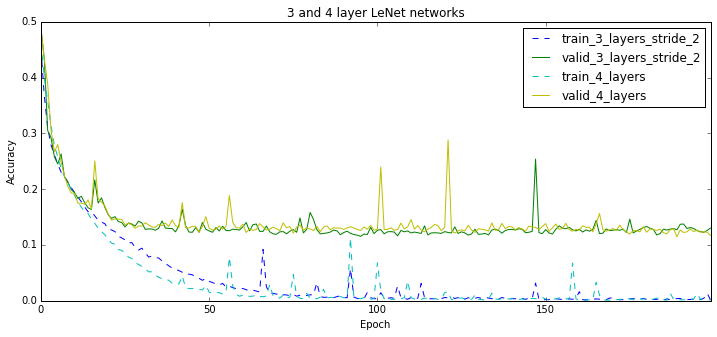
Maybe 8 layers is just too deep? In the previous post, I figured that 4-layer LeNet works better than 3-layer LeNet. But instead of going deeper, one can just consider images of smaller resolution, or what is vaguely equivalent to that, use a stride in the bottom layer.
The plots below show that a 6-layer VGG feels a lot better than an 8-layer one. This is not that case however for the 3-layer LeNet. It seems to perform worse than the 8-layer one, perhaps because it is “not non-linear enough”. Indeed, 3 layers is not a lot these days…
After this post, my champion is 6-layer VGG with 94.8% accuracy on the validation set.