Batch normalization - 95.9%
A big issue for my latest training experiments was the training speed. When an 8-layer VGG was trained with dropout, even 8 epochs did not really seem sufficient. This is exactly the context in which batch normalization was invented. Batch normalization is a technique that allows to speed up the training a lot and often drop regularization. It works as follows:
-
for each minibatch, the inputs of each unit are shifted and rescaled to look like if they are coming from a Gaussian
-
the transformed inputs are shifted and scaled again, but this time with trainable scaling and shift parameters and respectively. This makes the next layer “feel” that its inputs are coming from a distribution that it prefers.
-
running averages of per-batch statistics are kept to become a part of the final trained network
I tried two variants of batch norm: mean-only version, that only shifts the data, and the full one. The results are… overwhelming, let’s say:
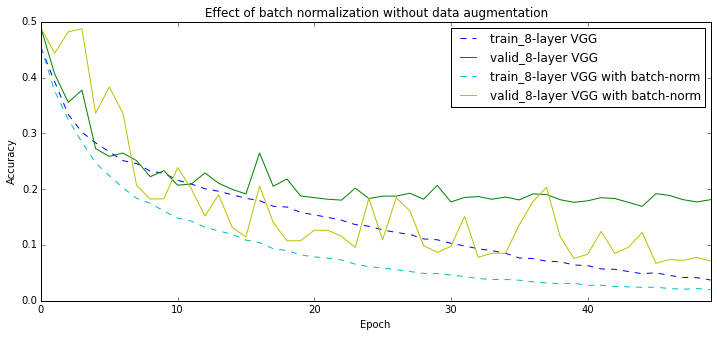
BOOM, applying batch normalization to my 8-layer VGG network brings me almost as far as additional data augmentation combined with dropout do. It is interesting however, that in the very beginning of the training the batch normalized network performs worse. Here is my of understanding what’s going on: with my rather small batch size of 100 a lot of noise is introduced into the training procedure. This is a great regularizer, but it also hurts the normalization machinery a bit.
Finally, I tried to combine batch normalization with my data augmenation and dropout:
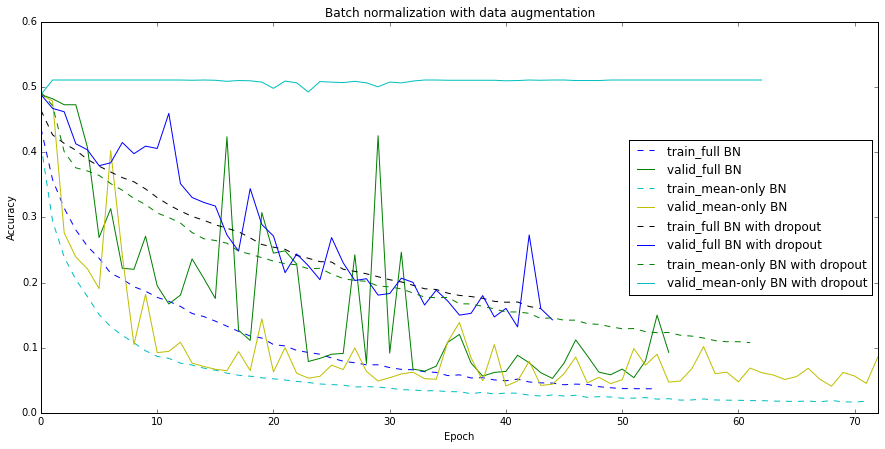
The mean-only batch norm feels much better in the presence of random cropping and provides me with the new champion (95.9% on the validation set, 95.28% on the test set). Adding dropout slows down training a lot for the mean-only version and drives the full batch norm crazy.